Google Translate versus gender bias
How does Google Translate handle gender-ambiguous input? With difficulty.
 Michal Měchura
Michal Měchura2023-01-27
Google has been trying to “solve” gender bias in machine translation since as far back as 2018. That’s when they published their first-ever blog post on the subject and that’s when they first unveiled a feature in Google Translate which gives you not one but two translations for some queries. You can see it in action for yourself if you go to Google Translate and ask it to translate “I am a doctor” from English into Spanish. It will give you two translations, one with “male doctor” and one with “female doctor”. They call this gender-specific translations and it is available in a handful of language pairs, both from English (notably English to Spanish) and into English (eg. Turkish to English).
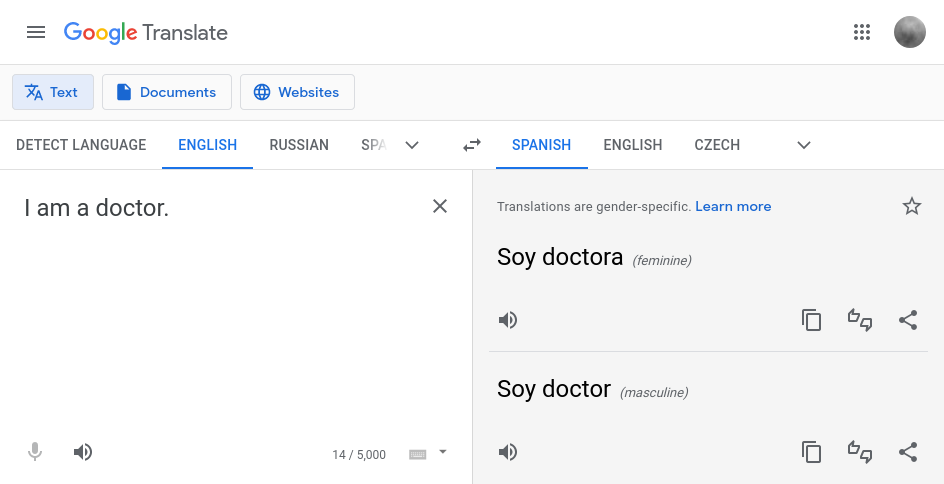
As you may know, Fairslator has a feature like this too, although in different language pairs (currently: English to French, German and Czech). So the interesting question is, how do the two compare? What’s same, what’s different, and which is better? In this article I’m going to discuss how Google is “doing” gender-specific translations and talk about the differences between their approach and Fairslator’s.
Difference 1: how it works inside
How does Google’s gender-specific translation feature work inside? Fortunately, Google is not too secretive (unlike DeepL), they have published blog posts and academic papers which explain in broad terms how they have done it.
They have obviously experimented with different strategies and even changed course completely at least once. Their original solution from 2018 was based on the idea that you “pre-edit” your training data by inserting invisible gender tokens into the source-language side, and then you machine-learn your translator from that. The translator is then able to take an input, insert the same invisible gender tokens into it, and produce separate “masculine” and “feminine” translations.
Then, sometime around the year 2020, they changed their mind and adopted a different strategy. They’re no longer pre-editing the training data. Instead, they allow their machine-learned models to produce gender-biased translations as before, and they rewrite them now. Rewriting is an additional step which happens after the translation is produced but before it is shown to a human user. It takes a target-language text which is gender-biased in one way and biases it the other way (for example from male doctor to female doctor).
If you know anything about Fairslator you will immediately notice that this, Google’s post-2020 strategy, is similar to how Fairslator is doing it. Fairslator too works by rewriting the output of machine translation. In fact, that’s how Fairslator is able to work with any machine translator (not just Google but also DeepL and others): it treats the translator as a black box and only looks at its output, scanning it for evidence of bias and rewriting it if necessary.
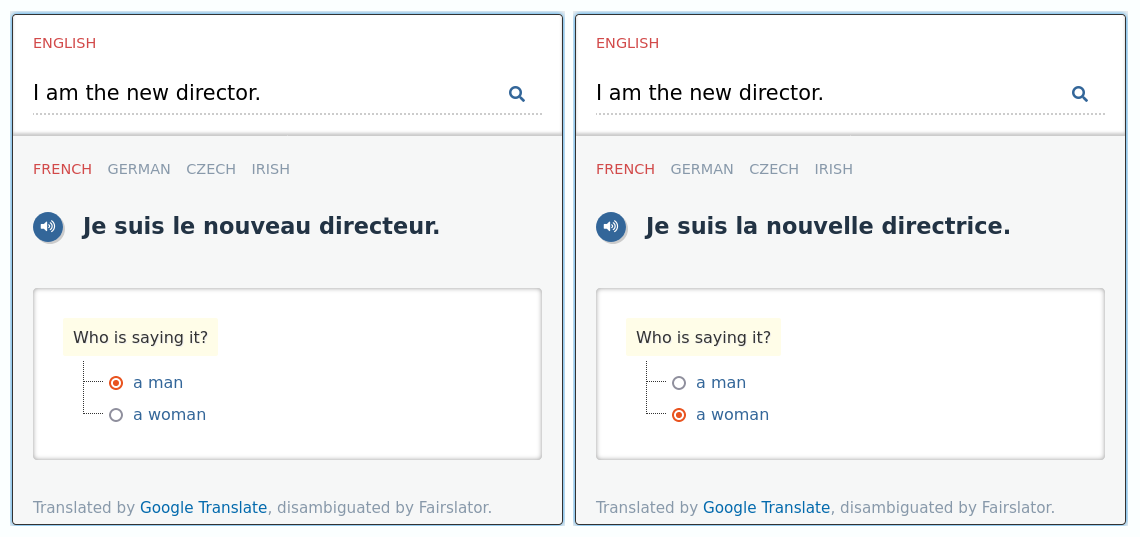
So yes, both Google and Fairslator have the same strategy: rewriting. In Fairslator I call it reinflection but it’s more or less the same thing. The biggest difference, though, is that Google’s rewriting algorithms are machine-learned and probabilistic, while mine (Fairslator’s) are hand-coded and rule-based. I am not going to argue which is better or which produces better results, but consider this: Google’s approach probably requires large amounts of training data, a powerful machine-learning infrastructure and a big team of people (just look at the long lists of acknowledgements in their blog posts), while I was able to produce comparable results just by spending a few afternoons hand-coding reinflection rules on my laptop. I suspect that rewriting/reinflection is a task easily solvable by old-fashioned, rule-based, lexicon-powered tech and that throwing machine learning at it is an overkill. But, of course, this is just my personal hunch and I could be wrong. We won’t know until somebody has done a proper comparative evaluation.
I have noticed one important difference between Google and Fairslator though. Google’s gender algorithms seem to spring into action only on simple textbook-like sentences such as “I am a doctor”. If you give it a more complex real-world sentence where the gender-ambiguous word is somewhere deep down the syntax tree, it seems to give up and returns only a single (biased) translation. Fairslator doesn’t give up on complex sentences. Try it with something like this: “The nurse kept on trying to save the patient’s life even after the doctor gave up.”
Difference 2: the user experience
When Google Translate gives you two translations instead of one, the translations are given side-by-side and labelled “feminine” and “masculine”. I wouldn’t be so sure that everybody always understands what these labels mean. These are technical terms from linguistics. In a sentence such as “How do you like your new doctor?” is it clear that “feminine” means “use this translation if you mean a female doctor”? A linguistically naive user (that is, most people) might not be sure.
Another potential problem I see is that, for somebody who doesn’t speak or read the target language, it is not obvious who the “masculine” and “feminine” labels apply to. The doctor, the ‘you’, or perhaps myself when I say the sentence? All that the label is saying is that “there is something maculine” and “there is something feminine” about this sentence – but what?
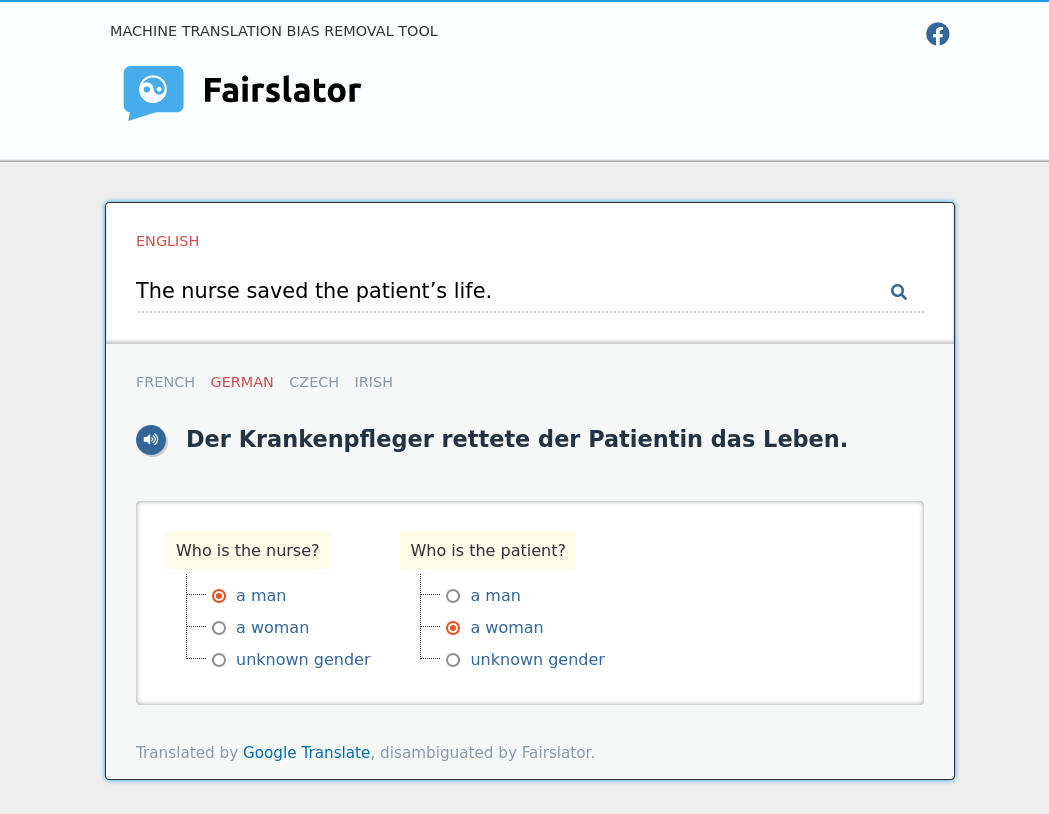
Fairslator is more, let’s say, informative about these things. Fairslator helps you choose the right translation by asking disambiguation questions which reuse words from the source-language sentence, such as “Who is the doctor? A man or a woman?” With questions like these, we are telling the human user exactly who the gender dictinction applies to, and we are saying it with everyday words the user is likely to understand: “man” and “woman”, not “masculine” and “feminine”.
I don’t know why Google has decided to give their users such a spartan, uninformative user experience. But maybe they haven’t exactly decided that, maybe it’s a consequence of the technology they have under the hood. Their algorithms for detecting and rewriting biased translations have probably been trained to know that there is something feminine or masculine about the sentence, but they don’t know what it is. To be able to machine-learn such things would require a training dataset of a kind that doesn’t exist. Fairslator, on the other hand, is not dependent on training data. Fairslator consists of hand-coded rules which are able to discover exactly the information that Google is missing: who the gender distinction applies to.
Conclusion
I know what you’re thinking: the Fairslator guy has written an article comparing Google Translate and Fairslator, and surprise surprise, Fairslator comes out as the winner. So let me summarize what I’m claiming and what I’m not.
I’m not claiming that Fairslator’s rule-based algorithm has better coverage, better precision or better whatever metric, compared to Google Translate’s machine-learning approach. All I’m saying is that Fairslator’s performance seems comparable to Google’s on simple sentences, and seems to exceed Google’s on complex sentences. The final verdict would have to come from a comprehensive evaluation, which I haven’t done (yet).
What I am claiming is that Fairslator provides a better user experience. It puts easy-to-understand disambiguation questions to the users, guiding them towards the correct translation even if they don’t speak the target language. This is a subjective judgement, but I really do think Google has underestimated the importance of the user experience here.
Google is obviously very interested in gender bias, if their publicly visible research output is anything to go by. They talk about it often at NLP conferences and they’ve published quite a few papers on the subject. But the tech they’ve developed so far is not fully baked yet.















